cmd/compile: poor register allocation with PGO #58298
Comments
|
CC @golang/runtime |
|
Thanks, I can reproduce this: I modified the repo slightly to disable logging and turn it into a benchmark: Deleplace/pgo-test@main...prattmic:deleplace-pgo-test:prattmic I used 82 copies of https://en.wikipedia.org/wiki/File:Example.jpg as the input. As an aside (I don't think this should affect PGO), your included profiles spend a lot of time in |
|
Thinking about this more, I think it's actually a Darwin-specific issue where newly-mapped memory has If I'm right, what's really annoying is Darwin goes against every other platform in this respect, where we want to |
|
My before/after profiles (for 10x runs of the benchmark): profiles.tar.gz After PGO, the benchmark takes ~3 cpu-s extra. ~2 of those are from I haven't looked closely yet, but I'm guessing inlining has some bad effects on further optimizations which result in a worse output. |
|
Thanks Michael and Michael, I wasn't aware yet that (1) Darwin was special here and (2) inlining could have bad effects on performance, besides increasing the binary size. |
|
@mknyszek I relaunched my original scripts on Linux amd64, and observed the same ~5% perf loss. My best guess is that the cause is not specific to Darwin. |
|
@prattmic I can confirm your awesome findings on my Linux amd64:
The binary size after PGO remains almost the same, it does not seem that inlining has occurred recklessly at too many call sites. We do seem to spend 200% of normal time inside |
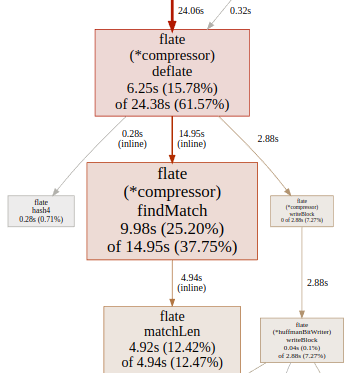
|
To be clear, what I mentioned has nothing to do with PGO; Darwin isn't special for PGO. I was just investigating something else that looked off in the profile you provided. |
|
I spent a while today looking at profiles and binary diffs (which was fun!) for In summary:
Before: After:
Before: After: |
|
At a high level, I'll say that this application isn't a great fit for PGO today because it isn't "diverse" enough. That is, it spends almost all of its time in a very small number of functions. Right now, PGO works best with programs with hundreds of hot functions, allowing it to accumulate small wins from many places. That said, we've said that we don't want PGO causing regressions, so I still would like to get this back closer to no regression. |
|
I suspect that the second bullet above (the The profile does not should the entry to |
|
Yes, that's basically #15808. |
|
I spent more time on this today. While hoisting could perhaps help here, the ultimate problem seems to be completely useless loads. Here is the final assembly of the core loop:
The loads of R12, R15, and R10 at 540, 541, and 543 are useless; they are never used. In this analysis I looked specifically at the R10 load which is obviously useless without any extra context, as it is immediately overwritten by the next instruction. Why are we loading this? Here are the basic blocks after regalloc: And just before regalloc: (I've omitted b101 predecessor b99, but you can see it in the screenshot). From this diff it isn't clear why b103 adds a load to R10. We can get more context from This says that on entry ( Why does this block think it needs v490 in R10? The expected b101 wants v490 in R10 on entry because its other predecessor b99 ends with v490 in R10 (because b99's predecessor b95 loaded it into R10. You can see this in the image). However, b101 proceeds to immediately dump v490 and use R10 for its own purpose. Note that b101 doesn't need to write R10 back to the v490 stack slot (v1138). I think this is because at this point every SSA value still has its own "stack slot", so SSA semantics still apply, but I'm not certain. It seems to me that it should be possible for regalloc to remove R10 from its requested src state if it knows it will dump the register without needing a spill store. cc @dr2chase |

{kind=link}
|
Change https://go.dev/cl/471158 mentions this issue: |
… requirements
For the following description, consider the following basic block graph:
b1 ───┐┌──── b2
││
││
▼▼
b3
For register allocator transitions between basic blocks, there are two
key passes (significant paraphrasing):
First, each basic block is visited in some predetermined visit order.
This is the core visitOrder range loop in regAllocState.regalloc. The
specific ordering heuristics aren't important here, except that the
order guarantees that when visiting a basic block at least one of its
predecessors has already been visited.
Upon visiting a basic block, that block sets its expected starting
register state (regAllocState.startRegs) based on the ending register
state (regAlloc.State.endRegs) of one of its predecessors. (How it
chooses which predecessor to use is not important here.)
From that starting state, registers are assigned for all values in the
block, ultimately resulting in some ending register state.
After all blocks have been visited, the shuffle pass
(regAllocState.shuffle) ensures that for each edge, endRegs of the
predecessor == startRegs of the successor. That is, it makes sure that
the startRegs assumptions actually hold true for each edge. It does this
by adding moves to the end of the predecessor block to place values in
the expected register for the successor block. These may be moves from
other registers, or from memory if the value is spilled.
Now on to the actual problem:
Assume that b1 places some value v1 into register R10, and thus ends
with endRegs containing R10 = v1.
When b3 is visited, it selects b1 as its model predecessor and sets
startRegs with R10 = v1.
b2 does not have v1 in R10, so later in the shuffle pass, we will add a
move of v1 into R10 to the end of b2 to ensure it is available for b3.
This is all perfectly fine and exactly how things should work.
Now suppose that b3 does not use v1. It does need to use some other
value v2, which is not currently in a register. When assigning v2 to a
register, it finds all registers are already in use and it needs to dump
a value. Ultimately, it decides to dump v1 from R10 and replace it with
v2.
This is fine, but it has downstream effects on shuffle in b2. b3's
startRegs still state that R10 = v1, so b2 will add a move to R10 even
though b3 will unconditionally overwrite it. i.e., the move at the end
of b2 is completely useless and can result in code like:
// end of b2
MOV n(SP), R10 // R10 = v1 <-- useless
// start of b3
MOV m(SP), R10 // R10 = v2
This is precisely what happened in #58298.
This CL addresses this problem by dropping registers from startRegs if
they are never used in the basic block prior to getting dumped. This
allows the shuffle pass to avoid placing those useless values into the
register.
There is a significant limitation to this CL, which is that it only
impacts the immediate predecessors of an overwriting block. We can
discuss this by zooming out a bit on the previous graph:
b4 ───┐┌──── b5
││
││
▼▼
b1 ───┐┌──── b2
││
││
▼▼
b3
Here we have the same graph, except we can see the two predecessors of
b1.
Now suppose that rather than b1 assigning R10 = v1 as above, the
assignment is done in b4. b1 has startRegs R10 = v1, doesn't use the
value at all, and simply passes it through to endRegs R10 = v1.
Now the shuffle pass will require both b2 and b5 to add a move to
assigned R10 = v1, because that is specified in their successor
startRegs.
With this CL, b3 drops R10 = v1 from startRegs, but there is no
backwards propagation, so b1 still has R10 = v1 in startRegs, and b5
still needs to add a useless move.
Extending this CL with such propagation may significantly increase the
number of useless moves we can remove, though it will add complexity to
maintenance and could potentially impact build performance depending on
how efficiently we could implement the propagation (something I haven't
considered carefully).
As-is, this optimization does not impact much code. In bent .text size
geomean is -0.02%. In the container/heap test binary, 18 of ~2500
functions are impacted by this CL. Bent and sweet do not show a
noticeable performance impact one way or another, however #58298 does
show a case where this can have impact if the useless instructions end
up in the hot path of a tight loop.
For #58298.
Change-Id: I2fcef37c955159d068fa0725f995a1848add8a5f
Reviewed-on: https://go-review.googlesource.com/c/go/+/471158
Run-TryBot: Michael Pratt <mpratt@google.com>
TryBot-Result: Gopher Robot <gobot@golang.org>
Reviewed-by: Keith Randall <khr@golang.org>
Reviewed-by: Cherry Mui <cherryyz@google.com>
Reviewed-by: David Chase <drchase@google.com>
|
Change https://go.dev/cl/484215 mentions this issue: |
ssagen.ssafn already holds the ir.Func, and ssa.Frontend.SetWBPos and ssa.Frontend.Lsym are simple wrappers around parts of the ir.Func. Expose the ir.Func through ssa.Frontend, allowing us to remove these wrapper methods and allowing future access to additional features of the ir.Func if needed. While we're here, drop ssa.Frontend.Line, which is unused. For #58298. Change-Id: I30c4cbd2743e9ad991d8c6b388484a7d1e95f3ae Reviewed-on: https://go-review.googlesource.com/c/go/+/484215 Auto-Submit: Michael Pratt <mpratt@google.com> TryBot-Result: Gopher Robot <gobot@golang.org> Reviewed-by: Cherry Mui <cherryyz@google.com> Run-TryBot: Michael Pratt <mpratt@google.com>
|
https://go.dev/cl/471158 targeted one of the problems in this workload, but it didn't make a huge difference. Here is the current status: Comparing just 1.21, we see there is still ~8% regression with PGO: |
|
Thank you Michael |
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes
What operating system and processor architecture are you using (
go env)?go envOutputWhat did you do?
I wanted to try the amazing PGO (Profile Guided Optimization) new capability of Go 1.20.
For this I wrote a program that converts all JPEG files in a directory into PNG. It is mostly CPU/memory-bound, with some I/O to read and write the local filesystem.
I wanted to observe:
I tried 6 settings: {sequential, concurrent} x process {3, 10, 82} images.
Source at https://github.com/Deleplace/pgo-test
To create the 6 profiles easily, I executed
main()inside a test:To create the 6 PGO-optimized executables:
What did you expect to see?
What did you see instead?
The PGO-enabled programs always seem a bit slower than the original program, regardless of the exact inputs used to produce the profiles.
The text was updated successfully, but these errors were encountered: