runtime: bgsweep does not yield to netpoller-readied goroutines #56060
Comments
|
CC @mknyszek @golang/runtime |
|
In #54767 I suggested that we treat the background sweeper the same way we treat idle mark workers. That seems like it would fix this? Unfortunately I think that requires additional logic in |
I think that would work, however we would need to get |
|
I'm not sure whether this is specific to Is there a supported way for application code to do low-priority / non-latency-sensitive background work, if not through calls to What if |
Thinking about this again, what if instead of deprioritizing the global run queue case, I understand where you're coming from on the point that |
|
So instead of deprioritizing the entire global run queue case, it would deprioritize the "global run queue has a single entry, which is the goroutine this P just put there" case? Yes, that sounds good. Can you check my understanding below? Thanks. I've sketched it with a note attached to the P. Maybe it could be global; the global run queue is global anyway. But I've also seen recently (in go1.18.8) that it's possible for the sweeper to run on two Ps (the bgsweep goroutine, and a goroutine that made an explicit call to There are three calls from We'd change the behavior of the second
|
|
Change https://go.dev/cl/449735 mentions this issue: |
|
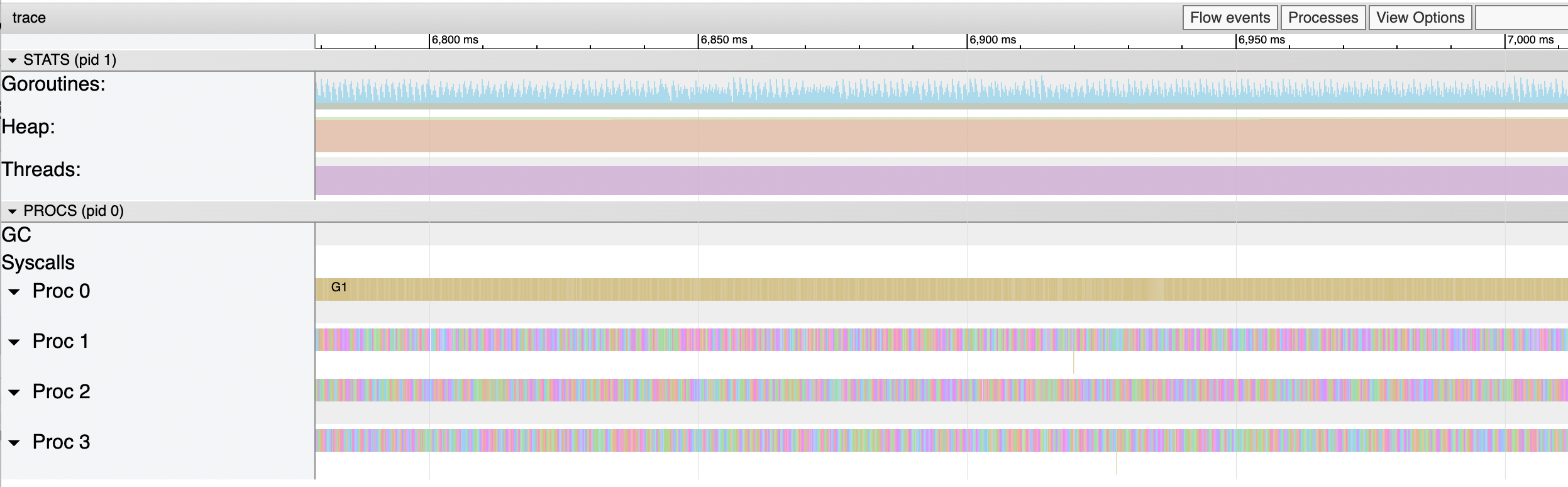
Here's a reproducer with user code calling This reproducer uses GOMAXPROCS-1 goroutines to create and rejoin a handful of workers (10), each of which do 100µs work units. These newly-created goroutines should end up in the P's local run queue. It uses one goroutine to do 100µs work units, interspersed with calls to Here's a 200ms view of the execution trace from the CL's parent (with this issue present). The goroutine that calls Gosched captures Proc 0, while the other 30 goroutines (each of 3 worker managers creates 10) doing the same kind of work share the other 3 Ps. (The single color of goroutine regions on Proc 0 indicates there's only one goroutine that it runs.)
Here's a 200ms view of the execution trace with CL 449735 (with this issue at least partially fixed). All processors run a variety of goroutines.
The issue isn't entirely gone; two goroutines can work together to capture a P. This zoomed-in view of CL 449735's execution trace (covering a few hundred microseconds) shows Proc 2 switching between the user goroutine that calls Gosched and the bgsweep goroutine. The sweeper shows up in tiny gaps between G19's executions. The reproducer I wrote doesn't cause much GC sweep work (so Proc 2 doesn't stay captured for long), but I expect that the effect could continue for as long as the sweeper (or other Gosched-calling goroutine) is running/runnable.
|


|
Thanks for the change and the in-depth analysis. I think this is leading me to conclude that the only solution to The fact that two arbitrary user Part of the difficulty for me here is defining what spirit of |
|
Intuitively I think that |
|
Yes, from what I've seen in the last few releases, the idle priority mark workers seem to behave pretty well: they yield to other work, and they're able to keep working for hundreds of microseconds without (as far as I see) spending lots of their P's time interacting with the scheduler. For what it's worth, I have the same intuition on the spirit of The global run queue is global of course (so only scales so well on larger machines), but I'm also uneasy about behaviors that require visiting each P. We have that already with Maybe Gosched could put more than the calling goroutine in the global runq. A carefully-managed system goroutine (similar to fing) could precede the goroutine that called Gosched (if it's not already Runnable), and could force the P that runs it to have a particular scheduling behavior, like "run the netpoller and stealWork, perhaps after pushing your local runq to the head of the globrunq (so the results of stealWork are run first)". That system goroutine would put itself to sleep until the next Gosched call. In an app with lots of Gosched use and lots of depth to the global runq, that system goroutine would be enqueued in the global runq only once at a time, which could help make this behavior cheaper as the app gets busier. |
That seems reasonable. My follow-up question with this is "how long" the goroutine remains in this state. I think we can all agree this isn't currently what
Treating
I think this is an interesting idea for idle priority goroutines in general. It's almost like the "idle process" equivalent of a goroutine. |
On the other hand, maybe that's OK? |
|
I'm not sure we're on the same page about the sweep work and I don't think it's right for all users of What I thought @ianlancetaylor was describing (and how I expect
If we kept track of a timestamp (or other monotonic counter, corresponding to position in the idealized global queue above) for when each goroutine transitioned into the Runnable state, and a timestamp for when a goroutine called My CL (449735) definitely has the exploitable loophole you describe. It's not a new loophole, and it's smaller than without the CL (takes two colluding goroutines, rather than only one), but it's certainly still present. Is it good to have at least a partial fix, or should we hold off on half measures? If you think there's potential in the "Maybe Gosched could put more than the calling goroutine in the global runq" / "force the P that runs it to have a particular scheduling behavior" idea @mknyszek ? I could try it out, but |
|
Ah, got it. I misunderstood what you were saying. I think we're on the same page now, thanks for clarifying.
This sounds right. I think a ticket system (where each Gosched increments the next ticket number, creating the barrier you describe) is an interesting idea, actually. It's a lot like the various generation counters we have. The only downside is that would have to be a single global resource. But yeah it's also complex, which is what I assume you mean by not a practical implementation strategy, haha.
I'm personally not opposed to landing what you have in general, but I think it might be too close to the freeze to land now. I don't expect it to have many merge conflicts just sitting around, and the freeze is shorter this time around (hopefully). I'm happy to review and iterate with you on it, and I can land it when the tree opens. FWIW, I'm holding back some of my own changes as well, so you won't be alone. :P Plus it gives us some time to bake this a little more.
Yeah... you have a point about fing. I'm not sure if it's worth it. |
When
bgsweepyields, it puts itself on the global run queue. When its P looks for work, the P finds that same goroutine in the global run queue before considering other Ps' local run queues. This results in bgsweep running at higher priority than any sort of work that gets enqueued in a P's local run queue (such as from the netpoller, which may be the easiest type to see in execution traces).For a 4-thread process, this means the GC consumes 1/4 of available processing time for longer than I'd expect (and perhaps longer than necessary). And if I understand this behavior correctly, a 2-thread process could end up spending 1/2 of its available processing time running GC-related code, in excess of the GC's "25% overhead" design goal.
CC @golang/runtime
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
I haven't checked since this week's release of go1.19.2 (though the change log for that doesn't mention anything related). I also haven't checked after https://go.dev/cl/429615 (for issue #54767), which isn't part of a stable release yet. That change still attempts to yield using
mcall(gosched_m).What operating system and processor architecture are you using (
go env)?The production system runs on a Linux / AMD64 VM that presents four hardware threads.
What did you do?
The service receives inbound HTTP requests, makes outbound HTTP requests to its dependencies, and does some calculation/processing. This allocates memory, and under load it does a GC cycle about twice per second.
What did you expect to see?
I expected the
runtime.bgsweepgoroutine to run at a very low priority, to yield its processor to other goroutines if any are runnable. I expected that to include goroutines that are made runnable as a result of inbound network traffic.What did you see instead?
In execution traces, I see the program keeping 3 of the 4 processors busy with user goroutines and 1 of the 4 processors busy with
runtime.bgsweep(Proc 3 in the image below). I see the count of runnable goroutines increase beyond zero, while bgsweep continues to yield and re-acquire its processor. I see goroutines made runnable by the netpoller wait up to several milliseconds before they're picked up by a processor (Proc 0 in the image below), during which the bgsweep goroutine is rescheduled over 1000 times (Proc 3).In Go 1.19, bgsweep calls
Gosched. In tip, it callsgoschedIfBusy. Both lead tomcall(gosched_m), which leads togoschedImpl(gp), which leads toglobrunqput(gp), which putsgpon the scheduler's global run queue.When a P finishes its current work and gets more from
findRunnable, it will sometimes find no "special" work (safe point function, trace reader, GC mark worker, finalizer), no work in its local run queue, and no work in the global run queue. It will then poll the network and enqueue it viainjectglist. When that has a P, and finds that there are no (other) idle Ps, it will place as many as it can (up to 256?) of the newly-runnable goroutines in its own local run queue. (I think the netpoller will only return 128 at a time. But this is a problem with even a small number of goroutines enqueued this way.)The P that had been running the
bgsweepworker needs new work, so it callsfindRunnable. It finds no "special" work, finds nothing in its own local run queue, and then checks the global run queue. There it finds thebgsweepgoroutine that it dropped off a moment earlier. It picks it back up and continues the sweep work.In the meantime, the goroutines that another P made runnable (because it grabbed everything that the netpoller had to offer) remain in a different local run queue. No P ever gets to the point of calling
stealWork.The text was updated successfully, but these errors were encountered: