runtime: non-spinning Ms spin uselessly when work exists #43997
Comments
|
CC @dvyukov |
|
Change https://golang.org/cl/288232 mentions this issue: |
|
For reference, here's an application reproducer similar to the one with which I diagnosed this issue (though quite a bit noisier):
https://golang.org/cl/288232 is a basic prototype that takes aim at the first sub-optimal bullet above by skipping the recheck entirely for non-spinning Ms, allowing them to stop. Before and after that CL, I get: This particular benchmark is unfortunately much noisier than my internal benchmark, but show promise (CpuTime samples are the sum of SystemTime and UserTime samples, so UserTime shouldn't be able to drop without both SystemTime and CpuTime flat). For reference, my internal workload for the same change: |
|
Interesting find! It's indeed very old and was present in the scheduler since the rewrite. I guess I added this work conservation check during late fine-tuning stage and failed to properly integrate it with the overall logic. I agree the current spinning behavior is bad and https://golang.org/cl/288232 looks like reasonable to me.
I think it should work. The invariant scheduler maintains is that there should be at least 1 spinning M if there is any work, and that 1 spinning M will wake up more if necessary. Since spinning Ms already checked workqueues of all Ps during steal phase, it looks reasonable to not re-do it again for all but last spinning M. That "delicate dance" re-checking is there only to prevent bad edge cases of not realized parallelism, it's not intended to be part of the performance story. |
|
Thanks for the extra background Dmitry! For posterity, here is what extreme cases of this can look like in the trace viewer. The pink regions are clumps of proc stop/start events where the non-spinning M is busy looping in findrunnable.
|
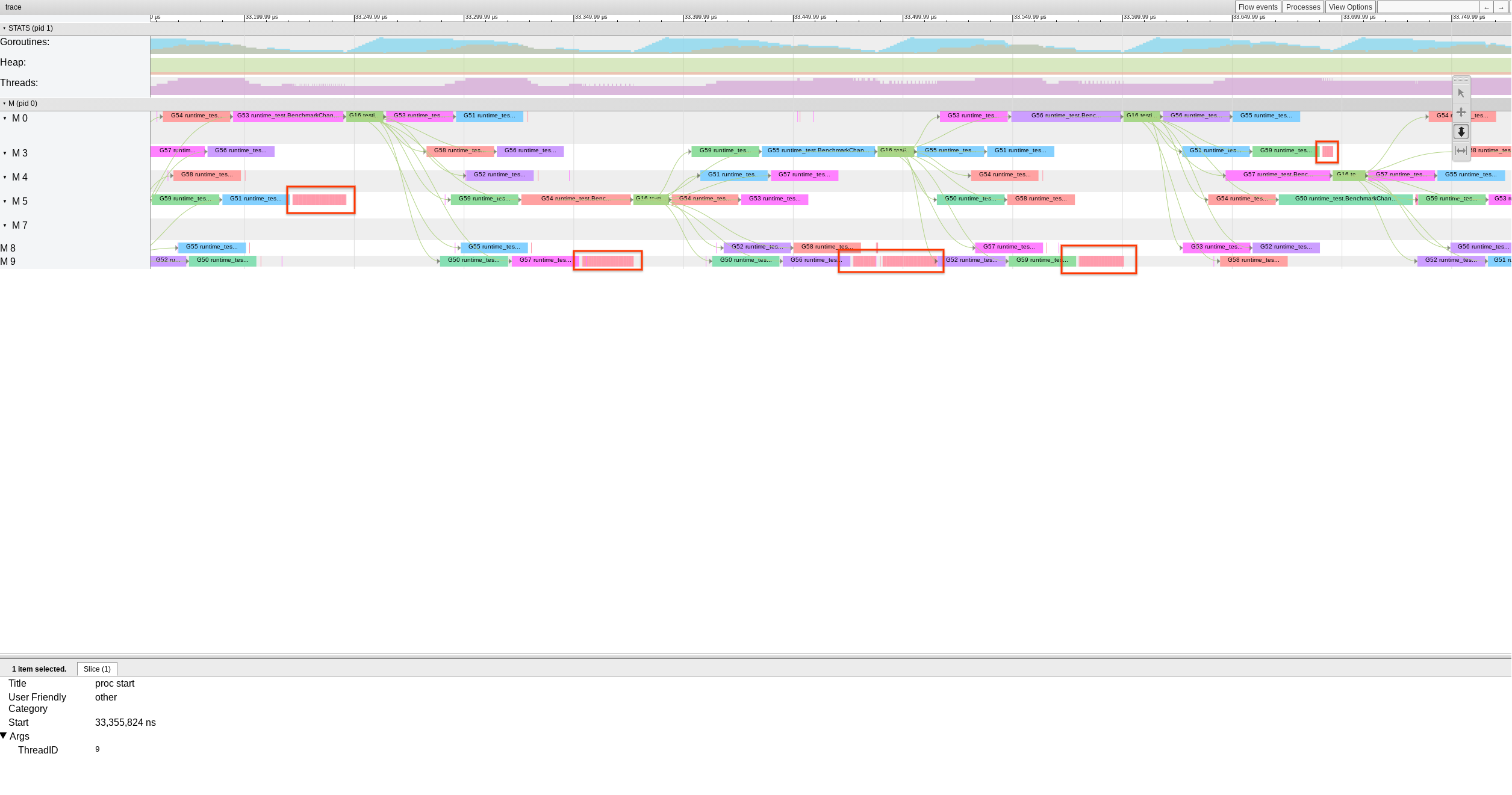
|
For what's it's worth, I also observed this behavior of the scheduler while working on the fix for #38860 and thought it was curious, but didn't worry about it since it was not the focus of my work at the time. That said, as the submitter of #28808 I welcome effort to improve the scheduler in this area. |
|
Change https://golang.org/cl/307914 mentions this issue: |
|
Change https://golang.org/cl/307913 mentions this issue: |
|
Change https://golang.org/cl/307910 mentions this issue: |
|
Change https://golang.org/cl/307911 mentions this issue: |
|
Change https://golang.org/cl/307912 mentions this issue: |
|
Change https://golang.org/cl/308654 mentions this issue: |
|
Change https://golang.org/cl/310850 mentions this issue: |
findrunnable has a couple places where delta is recomputed from a new pollUntil value. This proves to be a pain in refactoring, as it is easy to forget to do properly. Move computation of delta closer to its use, where it is more logical anyways. This CL should have no functional changes. For #43997. For #44313. Change-Id: I89980fd7f40f8a4c56c7540cae03ff99e12e1422 Reviewed-on: https://go-review.googlesource.com/c/go/+/307910 Trust: Michael Pratt <mpratt@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> TryBot-Result: Go Bot <gobot@golang.org> Reviewed-by: Michael Knyszek <mknyszek@google.com>
Here tryWakeP can't already be true, so there is no need to combine the values. This CL should have no functional changes. For #43997. For #44313. Change-Id: I640c7bb88a5f70c8d22f89f0b5b146b3f60c0136 Reviewed-on: https://go-review.googlesource.com/c/go/+/307911 Trust: Michael Pratt <mpratt@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> TryBot-Result: Go Bot <gobot@golang.org> Reviewed-by: Michael Knyszek <mknyszek@google.com>
The overview comments discuss readying goroutines, which is the most common source of work, but timers and idle-priority GC work also require the same synchronization w.r.t. spinning Ms. This CL should have no functional changes. For #43997 Updates #44313 Change-Id: I7910a7f93764dde07c3ed63666277eb832bf8299 Reviewed-on: https://go-review.googlesource.com/c/go/+/307912 Trust: Michael Pratt <mpratt@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> TryBot-Result: Go Bot <gobot@golang.org> Reviewed-by: Michael Knyszek <mknyszek@google.com>
findrunnable has grown very large and hard to follow over the years. Parts we can split out into logical chunks should help make it more understandable and easier to change in the future. The work stealing loop is one such big chunk that is fairly trivial to split out into its own function, and even has the advantage of simplifying control flow by removing a goto around work stealing. This CL should have no functional changes. For #43997. For #44313. Change-Id: Ie69670c7bc60bd6c114e860184918717829adb22 Reviewed-on: https://go-review.googlesource.com/c/go/+/307913 Trust: Michael Pratt <mpratt@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> TryBot-Result: Go Bot <gobot@golang.org> Reviewed-by: Chris Hines <chris.cs.guy@gmail.com> Reviewed-by: Michael Knyszek <mknyszek@google.com>
Break the main components of the findrunnable spinning -> non-spinning recheck out into their own functions, which simplifies both findrunnable and the new functions, which can make use of fancy features like early returns. This CL should have no functional changes. For #43997 For #44313 Change-Id: I6d3060fcecda9920a3471ff338f73d53b1d848a3 Reviewed-on: https://go-review.googlesource.com/c/go/+/307914 Trust: Michael Pratt <mpratt@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> TryBot-Result: Go Bot <gobot@golang.org> Reviewed-by: Michael Knyszek <mknyszek@google.com>
When rechecking for work after transitioning from a spinning to non-spinning M, checking timers before GC isn't useful. That is, if there is GC work available, it will run immediately and the updated pollUntil is unused. Move this check to just before netpoll, where pollUntil is used. While this technically improves efficiency in the (rare) case that we find GC work in this block, the primary motivation is simply to improve clarity by moving the update closer to use. For #43997 Change-Id: Ibc7fb308ac4a582875c200659c9e272121a89f3b Reviewed-on: https://go-review.googlesource.com/c/go/+/308654 Trust: Michael Pratt <mpratt@google.com> Trust: Michael Knyszek <mknyszek@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> TryBot-Result: Go Bot <gobot@golang.org> Reviewed-by: Michael Knyszek <mknyszek@google.com>
One reason that this would not work today is that we can optimistically increment |
|
Change https://go.dev/cl/389014 mentions this issue: |
CL 310850 dropped work re-checks on non-spinning Ms to fix #43997. This introduced a new race condition: a non-spinning M may drop its P and then park at the same time a spinning M attempts to wake a P to handle some new work. The spinning M fails to find an idle P (because the non-spinning M hasn't quite made its P idle yet), and does nothing assuming that the system is fully loaded. This results in loss of work conservation. In the worst case we could have a complete deadlock if injectglist fails to wake anything just as all Ps are going idle. sched.needspinning adds new synchronization to cover this case. If work submission fails to find a P, it sets needspinning to indicate that a spinning M is required. When non-spinning Ms prepare to drop their P, they check needspinning and abort going idle to become a spinning M instead. This addresses the race without extra spurious wakeups. In the normal (non-racing case), an M will become spinning via the normal path and clear the flag. injectglist must change in addition to wakep because it is a similar form of work submission, notably used following netpoll at a point when we might not have a P that would guarantee the work runs. Fixes #45867 Change-Id: Ieb623a6d4162fb8c2be7b4ff8acdebcc3a0d69a8 Reviewed-on: https://go-review.googlesource.com/c/go/+/389014 TryBot-Result: Gopher Robot <gobot@golang.org> Reviewed-by: Michael Knyszek <mknyszek@google.com> Run-TryBot: Michael Pratt <mpratt@google.com> Auto-Submit: Michael Pratt <mpratt@google.com>
Background: The scheduler differentiates "spinning" and "non-spinning" Ms. We will allow up to
GOMAXPROCS/2Ms to enter the spinning state (assuming all Ps are busy).Spinning Ms are eligible to steal runnable goroutines or timers from other Ps and will loop several times over all Ps attempting to steal before giving up and stopping.
For work conservation, the scheduler ensures that there is at least one spinning thread after readying a goroutine. To support this, spinning Ms adhere to a contract: any work submitted when sched.nmspinning > 0 is guaranteed to be discovered.
To maintain this invariant, spinning Ms must:
This is all good for spinning Ms, but there is a bad case for non-spinning Ms.
If there are already enough spinning Ms, the remaining Ms will skip the main steal loop and go “directly” to stop. However, after the stop label is the steal recheck primarily intended for spinning -> non-spinning transitions, but executed by all Ms.
A non-spinning M can detect work in this loop and jump back to the top to try to steal it (we don’t steal directly in this loop to avoid duplication of the somewhat complex stealing logic). Unfortunately this is a non-spinning M, so assuming other spinning Ms don’t go away we will remain non-spinning and skip right over the steal loop back to stop, at which point we’ll notice the same work again, jump to the top and start all over again.
Note that this can only occur while there is at least one spinning M, which means that this behavior is bounded: either the spinning M will take the work for itself or will take some other work and the non-spinning M can transition to spinning and take work for itself.
I argue that the current behavior is nearly always sub-optimal:
sched.nmspinningtotal available units of work, then the spinning Ms will take all of the work and the non-spinning one will have to ultimately sleep anyways.sched.nmspinningtotal available units of work, then the non-spinning M should eventually get some work. However, the current approach needlessly delays stealing until the existing spinning Ms have found work. I think it would be better if the non-spinning Ms could upgrade themselves to spinning (in excess of the normal GOMAXPROCS/2 limit) if they notice that there is extra work to do, as this would reduce scheduling latency without increasing work (remember that we are basically in a busy-loop anyways).I discovered this behavior on a Google-internal workload which is basically the worst case scenario for this: one M/P/G is running continuously generating very short-lived work that must be stolen by other Ms. The other Ms spend most of their time in the scheduler looking for work. A simple change to make non-spinning Ms skip the steal recheck reduces application wall time by 12% and CPU time by 23%. I hope to create a similar open source reproducer soon.
Note that this behavior has existed since the introduction of spinning Ms, so this is not a new regression.
Something that is not directly related, but perhaps worth investigating is whether we should even do all of the “delicate dance” checks on all spinning Ms, as it should not affect correctness to limit it to only the 1->0 nmspinning transition, which would further reduce usage.
cc @aclements @mknyszek
See also #18237, #28808
The text was updated successfully, but these errors were encountered: