runtime: memmove performance on arm64 for unaligned copies is poor on some CPUs #40324
Labels
FrozenDueToAge
NeedsInvestigation
Someone must examine and confirm this is a valid issue and not a duplicate of an existing one.
Performance
Comments
|
https://golang.org/cl/243357 has been submitted. Is there any additional work that should be done which is preventing this issue from being closed? |
|
Yes this issue can be closed. |
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
The following is indented to start a discussion about the performance of memmove on arm64 and the pros and cons of implementing micro-architecture aware flags to achieve better performance on varying CPUs. A pull request making the changes tested in the data below can be found here: https://go-review.googlesource.com/c/go/+/243357
What version of Go are you using (
go version)?tip of master branch (at the time of writing)
Does this issue reproduce with the latest release?
Yes
What operating system and processor architecture are you using (
go env)?arch: arm64
os: Amazon Linux 2
go envWhat did you do?
What did you expect to see?
I expected to see good performance across a range of systems on all of the memmove benchmarks.
What did you see instead?
On some CPUs, unaligned copies showed poor performance.
Data
The CPUs I used for testing are:
The new implementation has several new optimizations, as noted in the commit message:
Aligned copies
For aligned copies, performance improved by about 5% for the largest copies. The implementation without realignment performs slightly better, since it omits the overhead of checking the flag and performing the realignment.

And for Cortex-A53, the improvements were better. This could be because the A53 doesn't use out of order execution and the loads and stores in this implementation are manually reordered.
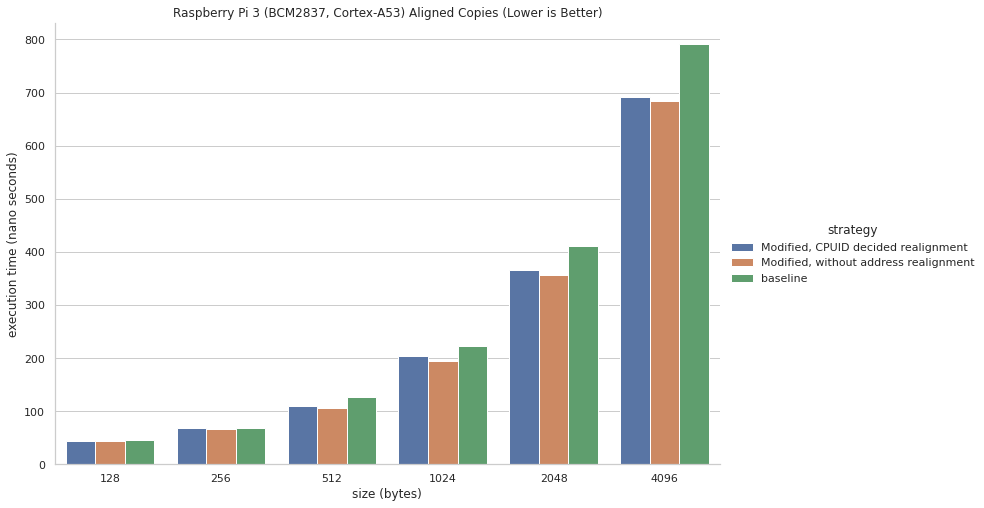
Unaligned Copies
For unaligned copies, the difference is more apparent. First we look at a Neoverse N1 CPU
The following compares:
Next, you can see in a Cortex-A72, the opposite alignement choice produces the best results.
The following compares:
Conclusion
For the proposed implementation, I chose to use CPUID to determine the micro architecture to select the best performing move for the target CPU. Since two of the test CPUs have opposite behavior regarding alignment, this flag also both CPUs (and hopefully others as well) to achieve good performance.
The text was updated successfully, but these errors were encountered: