runtime: RSS keeps on increasing, suspected scavenger issue #36398
Comments
|
Update: I tried again with go 1.13.0, this time strace captures many madv_free as expected: https://pastebin.com/Hwy2DKt4 |
|
@dbakti7 The Finally, Linux's With all that said, I'm not sure how to help with the RSS growth in your application unless you provide more information about its behavior (I don't mean specifics about the application, just how it interacts with memory). For example, is the heap itself growing really big? That is, if you run your service under |
|
@mknyszek Thanks for the elaborate explanation! And agree with your point regarding MADV_FREE and MADV_DONTNEED, problem is we are still unable to replicate our production load to see whether MADV_DONTNEED will improve our memory usage. :( Regarding our application behavior, I think the most notable characteristic is it's doing a lot of json and string manipulation, especially json marshal and unmarshal. Which I suspect is the cause of high velocity object creation. (Is memory fragmentation a possible culprit? I'm not sure how Go runtime handles memory reuse and fragmentation if service is creating many objects rapidly) |
That's odd. gctrace should print "X MiB released" times <= the number of syscalls you see in strace. I'll try this out.
To be clear, it'll just improve reported memory use.
It's fine to use in production. It doesn't print anything extra or do anything other than set a global variable.
It could be fragmentation, though I don't think we have fragmentation blow-up issues in the Go runtime's allocator like some other allocators have. One way to confirm this would be a high value of |
|
We just found out that our ever-increasing RSS in production is due to prometheus somehow consuming a lot of memory over time, so should not be due to our go application GC issue in this case. |
|
ouch, sorry, my bad.. I interpreted prometheus response wrongly. I thought go_mem_stats reported by prometheus endpoint refers to the memory usage of prometheus only. Seems like it's reporting the memory usage of the application itself. Metrics itself is small, so should not be prometheus memory issue. Sorry for the back-and-forth confusion, reopen ticket, will investigate further. |
From go MemStats reported by Prometheus ~ (4GB - 2GB) / 1.7GB ~ 1.13 In first container, heap_inuse is pretty notable (>1GB), but in second container it's very low (<100MB)
|
|
@dbakti7 The MemStats numbers indicate that everything is pretty much WAI; the OOMs however are not great and can be caused by a number of things. The high For now, can you provide the following details?
|
|
Hi @mknyszek
Full printout of
3.10.0
overcommit_memory: 1
No PS. On production, we are still using golang 1.9.4 |
|
I meet the same problem. I check it by pprof, BTW: I'm using go1.13.7 and go1.14.1. The env var here is my monitor(promethues) chart.
|
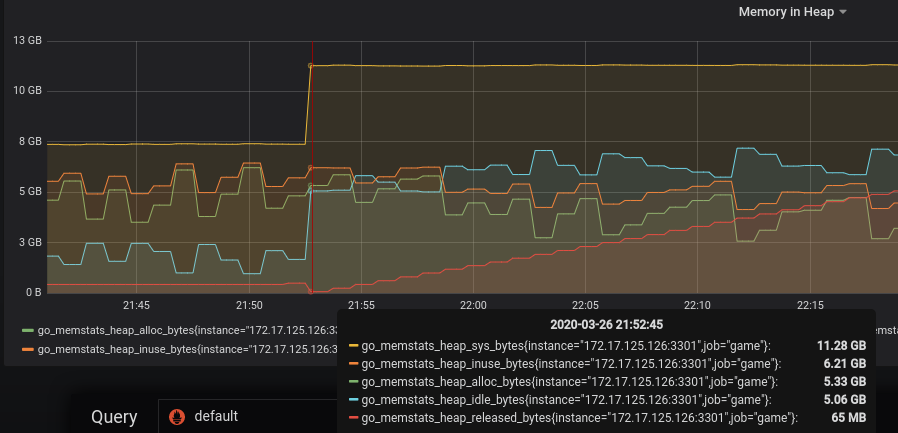


|
@dbakti7 Sorry about the very long delay in coming back to this. I don't have a good handle on what could be going wrong. Everything you've shared with me thus far suggests that things are working OK on the Go side. Did @cupen That looks to me like you have a heap spike at around 21:53 and the service is slowly recovering (note |
|
@dbakti7 Actually, looking back, it occurs to me that since you're on Linux 3.10.0, which doesn't have |
|
@markdryan The actually RSS was similar as the About As you said, I will file a new issue for my problem. |
|
According to |
|
@mknyszek really sorry for missing to reply. So maybe you are right about our service having "high memory peak usage". |
Can you explain why? If we understood the concerns, perhaps an alternative solution can be found. |
|
@davecheney no specific technical reason, it's more due to limitations imposed by our company policy in terms of data centre operations, i.e. no custom command is allowed in production environment. |
|
It's not a custom command, it's an environment variable, like |
|
Sorry if I used the wrong terminology. Basically we have a very strict requirements in making changes to any thing in production environment (including setting environment variable). It requires strong evidence and reasoning from developers. theoretically, madvdontneed should improve our situation further (refer to my original post where I provided the synthetic code)
|
|
Thank you for your reply. I have nothing further to add, but I encourage you to review this comment by @randall77 #39779 (comment) |
|
@davecheney Thank you for additional references. I'm pretty convinced with that statement now about how Go runtime works after multiple experiments. I'm okay to close this issue actually, until we found new information in the future. But I have one (slightly off-topic) question, if I may: |
|
I would inspect the overcommit settings for the respective kernels, the amount of swap configured, if any (linux behaves very differently in the presence of any amount of swap, even if it not used), and the respective memory loads of the machines--as @randall77 observed it is the decision of the kernel to seek to take back pages from a processes' working set based on overall memory pressure. |
|
Containers/cgroups also have a lot of memory controls, which Kubernetes could be configuring differently than your previous non-Kubernetes containers (it sounds like you were already running in containers, just not containers managed by Kubernetes?). In particular, I think a lower memory.soft_limit_in_bytes will cause the kernel to release |
|
@davecheney @aclements thank you for the pointers, I will check on these. |
|
@dbakti7 - just wanted to follow up on this. Is there anything else we can help with on this issue? It sounds like this needs further debugging from your end to properly categorize it as a bug in Go or not. |
|
Hi @agnivade! |
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes, similar symptoms shown with go 1.13.5.
What operating system and processor architecture are you using (
go env)?go envOutputWhat did you do?
We are experiencing RSS that keeps on increasing in one of our Go service. We are suspecting it's due to scavenger not returning memory to OS properly (or OS not taking back the memory due to use of MADV_FREE). Checked via pprof, no memory leak detected.
We tried some experiment with the following simple Go program:
running with
strace -q -e trace=memory go run main.goresults are not consistent:
running with gctrace, we got: https://pastebin.com/6JaC2r85
we confirmed that RSS remains high via top and pmap:
According to #30333, in go 1.13 scavenging should be performed periodically instead of waiting for the 5 minutes interval, but there is no MADV_FREE logged by strace sometimes. gctrace does print logs about scavenging, but seems like it's not really calling MADV_FREE? Am I missing something regarding this scavenging logic in go 1.13?
Tried with GODEBUG=madvdontneed=1, result is better, but RSS still hovering at around 500MB, only when we combine madvdontneed with debug.FreeOSMemory() then we got RSS < 30MB. Is this the only way to ensure Go is returning memory back to OS in Linux?
What did you expect to see?
RSS is gradually going down, or at least MADV_FREE captured by strace.
What did you see instead?
RSS remains high, no MADV_FREE captured by strace.
Additional notes: running the same program on windows with go 1.13 seems to have the desired effect, i.e. memory is gradually released back to OS.
The text was updated successfully, but these errors were encountered: