cmd/compile: CMOV instruction slower than branch #26306
Comments
|
@PeterRK What processor are you running? |
|
I've microbenchmarked the code here on my Core i7-4510U between go1.10.3 and go1.11beta1 and benchstat returns the following: This would indicate there is actually a 24% speed improvement between go1.10.3 and go1.11beta1. I can confirm that the difference is the use of the CMOV instruction in the down function. Here is the Benchmark function: |
|
For larger arrrays (size = 1000000) go1.11beta1 is getting slower. |
|
I have tried i7-8700 & i5-7500. test with 20M list: test code: |

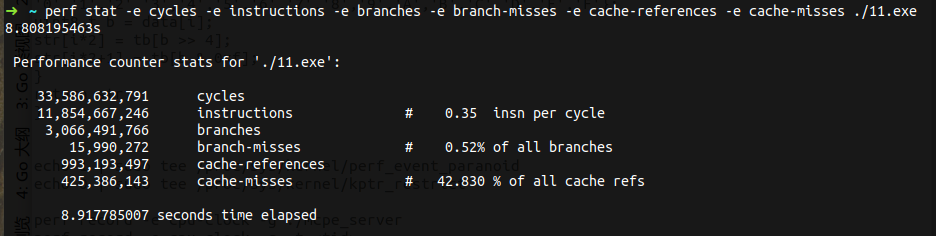
|
Here's an auto-contained benchmark that can be directly copy-pasted in a Here's the result with On a |
|
Thanks @ALTree for the self-contained benchmark. I was very interested in the CMOV instruction so I gave it a shot too. I see different results in my CPU ( Things look more or less same, except the last row, where I see perf improvement rather than a slowdown. For the Sorry if this just adds noise. I only posted because I saw different results in the last case. |
|
This might be related to #25298 as pointed out by @randall77 on golang-dev. See the discussion branch predictor versus CMOV. |
|
The benchmark code has the problem that after the first iteration slice a is already sorted. The new benchstat looks like this: Apparently branch prediction and speculative execution (loads) are faster than CMOV if the slice size exceeds the level 2 cache. |
|
Honestly, I'm not sure what to do. @TocarIP? |
|
go 1.11 vs go 1.10 on different scales: Go 1.11 loses its advantage when data size grows. CMOV causes that. |

|
I see similar things. I suspect there are two different issues - one with N=100 and one with large N. With a few more data points (old=tip with cmov generation turned off, new=tip): As the array gets larger, cmov gets relatively slower. My L3 cache is 10MB, which is N=1.25e6, just about at the inflection point. The array size dependence seems an awful lot like cache effects. If the array we're sorting fits in L3 cache, it is fast. If the array does not fit, it's slower. My suspicion is that when using branches, if the branch is predicted correctly (probably 50% of the time) we can issue the next read (the grandchild in the heap) in parallel with the current read. Using cmov, there's a data dependence from one load to the next, so we never issue two of them in parallel. That might be enough of an effect to explain the result - the cmov serializes the reads, and the cache miss is so slow that the branch mispredict & restart can all be hidden in the cache miss. It seems a pretty niche case where this effect comes into play. I wouldn't want to remove cmov generation because of it. |
|
I can somewhat verify my claim. I can add a prefetch to the benchmark and that mostly fixes the large N behavior. At the head of the loop in Now old=nocmov, new=tip: There is still some effect, but it is much reduced. |
|
Perhaps we could detect the fact that the result of a CMOV is used as an argument to a load, and suppress the use of a CMOV in those cases. That would allow the chip to continue to speculate the load. Seems like a pretty vague condition, though. And definitely not 1.11 material. |
|
Are there µ-arches where the CMOV doesn't block the speculative load? (That seems like the sort of thing that register renaming is supposed to take care of.) |
|
@bcmills I don't think so. The speculative load needs the address from which to load, and I don't know of any archs which speculate the address. With regular branches, With the |
|
Change https://golang.org/cl/145717 mentions this issue: |
|
Change https://golang.org/cl/168117 mentions this issue: |
What version of Go are you using (
go version)?go1.11beta1 linux/amd64
Does this issue reproduce with the latest release?
Yes.
What operating system and processor architecture are you using (
go env)?GOARCH="amd64"
GOBIN=""
GOCACHE="/home/rk/.cache/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/home/rk/GoSpace/Projects"
GOPROXY=""
GORACE=""
GOROOT="/home/rk/GoSpace/GO"
GOTMPDIR=""
GOTOOLDIR="/home/rk/GoSpace/GO/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build473408654=/tmp/go-build -gno-record-gcc-switches"
VGOMODROOT=""
What did you do?
I built the code below with go 1.10 and go 1.11.
https://play.golang.org/p/22MEbiXFpzo
What did you expect to see?
The binary built by go 1.11 is as fast as that built by go 1.10.
What did you see instead?
The binary built by go 1.11 is incredibly slower than that built by go 1.10.
Go 1.11 compiles the function "down" to assembly like this:
If replacing the CMOV instruction with a branch, it can be 80% faster.
The text was updated successfully, but these errors were encountered: